Adjacency-constrained hierarchical clustering of a band similarity matrix with application to Genomics
Résumé
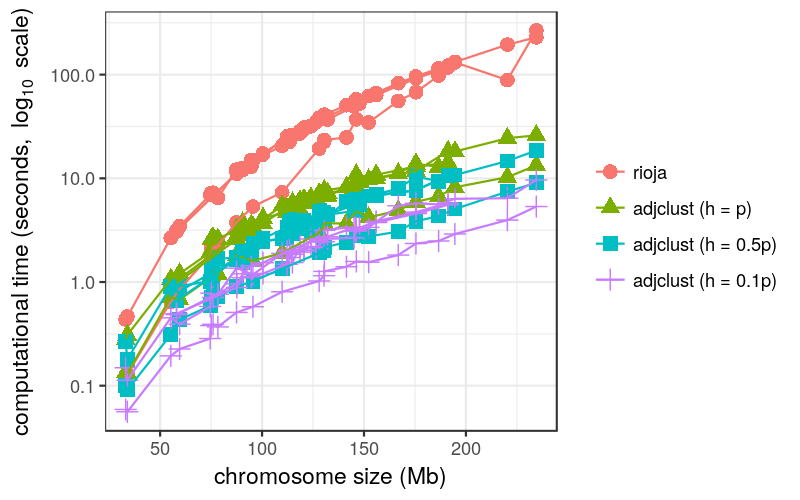
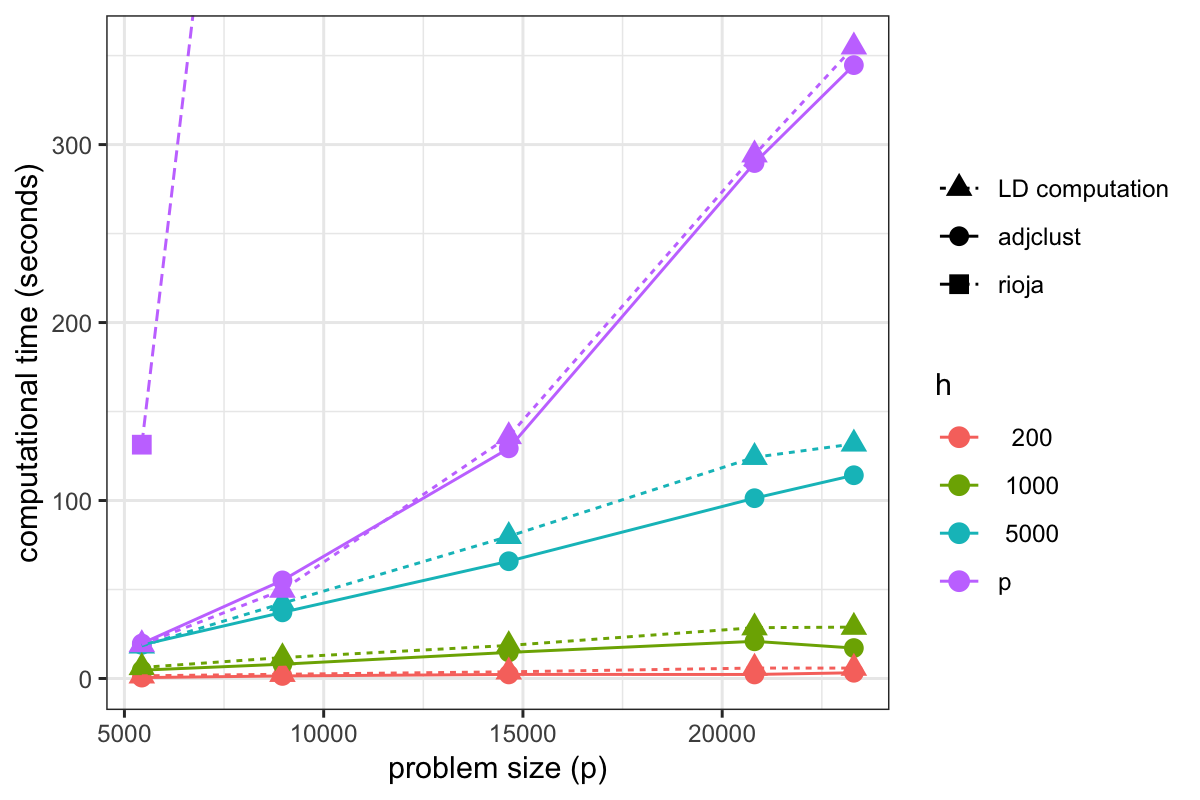
Motivation: Genomic data analyses such as Genome-Wide Association Studies (GWAS) or Hi-C studies are often faced with the problem of partitioning chromosomes into successive regions based on a similarity matrix of high-resolution, locus-level measurements. An intuitive way of doing this is to perform a modified Hierarchical Agglomerative Clustering (HAC), where only adjacent clusters (according to the ordering of positions within a chromosome) are allowed to be merged. A major practical drawback of this method is its quadratic time and space complexity in the number of loci, which is typically of the order of 10^4 to 10^5 for each chromosome.
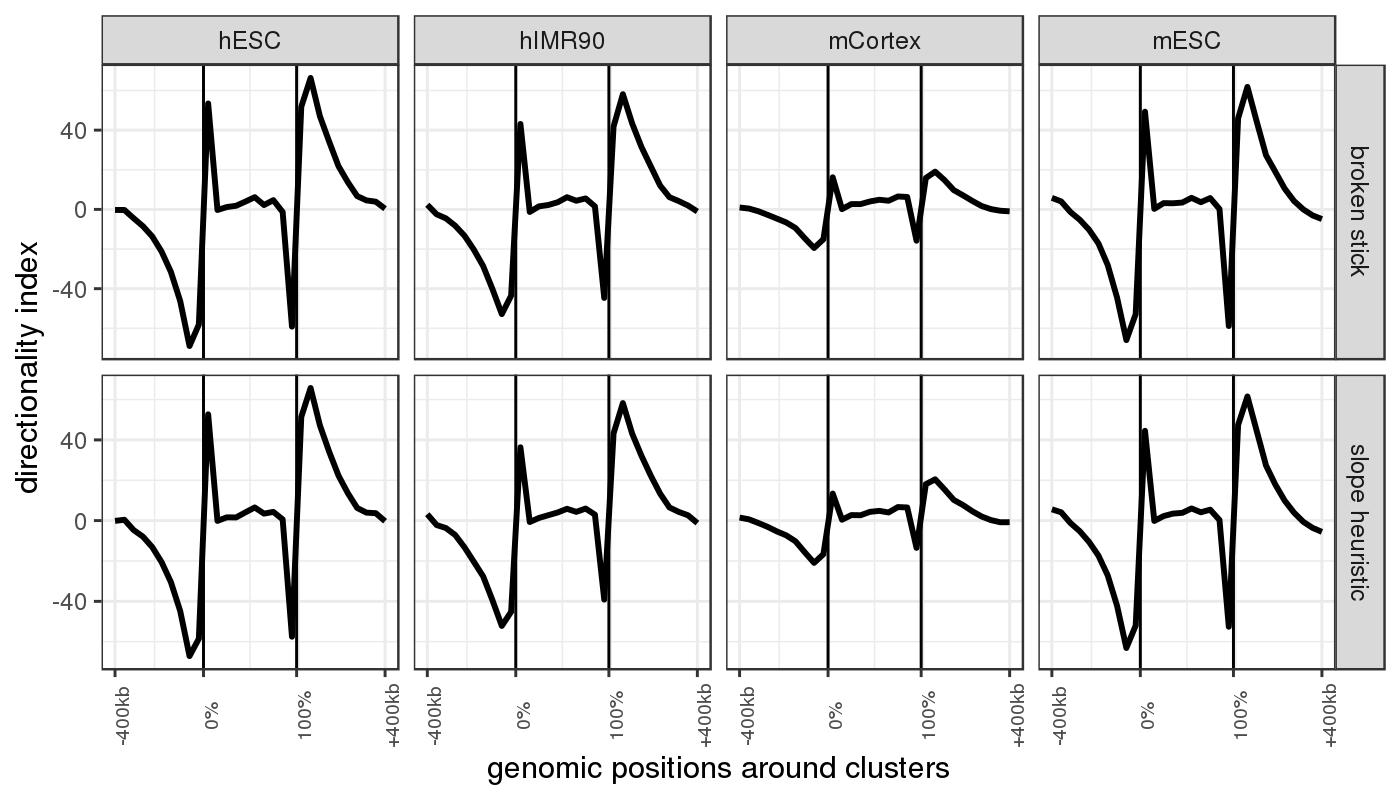
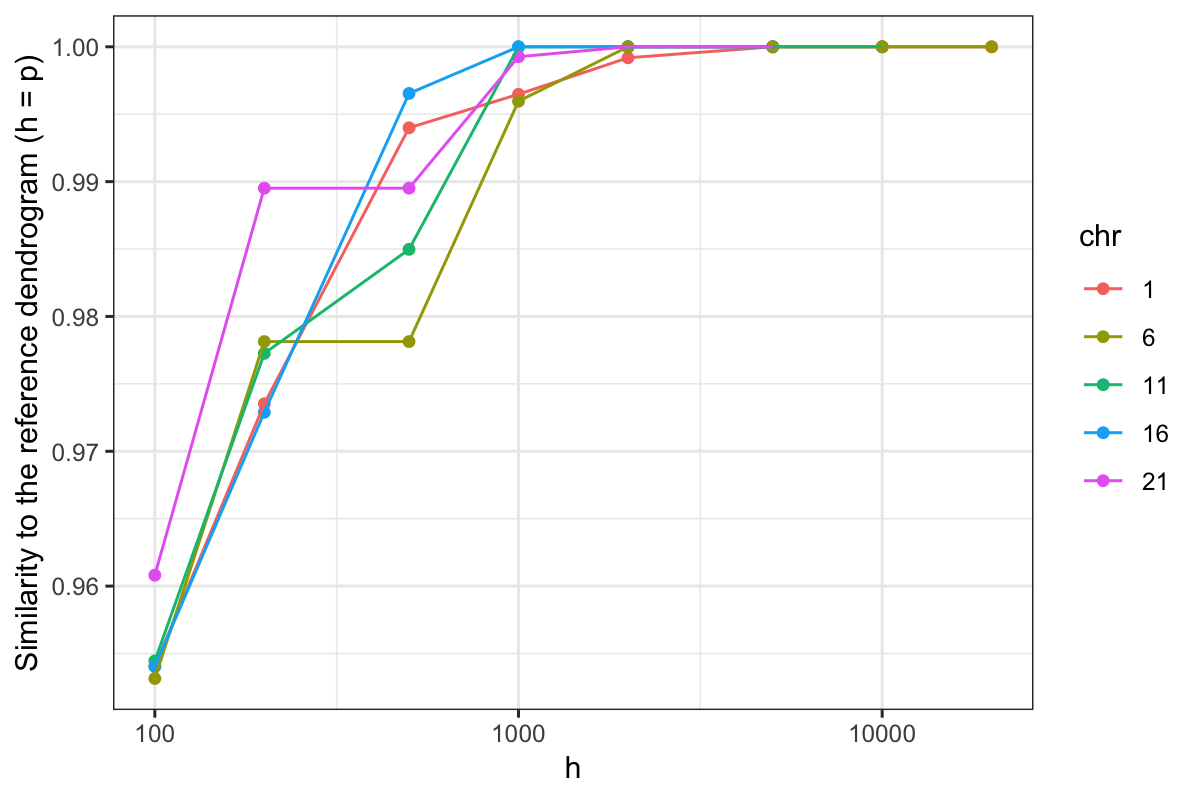
Results: By assuming that the similarity between physically distant objects is negligible, we propose an implementation of this adjacency-constrained HAC with quasi-linear complexity. Our illustrations on GWAS and Hi-C datasets demonstrate the relevance of this assumption, and show that this method highlights biologically meaningful signals. Thanks to its small time and memory footprint, the method can be run on a standard laptop in minutes or even seconds.
Availability and Implementation: Software and sample data are available as an R package, adjclust, that can be downloaded from the Comprehensive R Archive Network (CRAN).
Fichier principal
 ambroise_etal_AMB2019.pdf (703.99 Ko)
Télécharger le fichier
RLGH_heap_label+linkage_0.pdf (6.28 Ko)
Télécharger le fichier
RLGH_heap_label+linkage_1.pdf (6.39 Ko)
Télécharger le fichier
algo-chac.pdf (4.51 Ko)
Télécharger le fichier
algo-chac_fusion-labels.pdf (4.5 Ko)
Télécharger le fichier
ambroise_etal_AMB2019-suppmat.pdf (783.52 Ko)
Télécharger le fichier
article_comptime_dots.png (71.03 Ko)
Télécharger le fichier
article_di_full.png (62.2 Ko)
Télécharger le fichier
pencil_large_h.pdf (33.56 Ko)
Télécharger le fichier
pencil_small_h.pdf (33.55 Ko)
Télécharger le fichier
snp_comptime_p.png (121.99 Ko)
Télécharger le fichier
snp_firstDiff.png (103.31 Ko)
Télécharger le fichier
ambroise_etal_AMB2019.pdf (703.99 Ko)
Télécharger le fichier
RLGH_heap_label+linkage_0.pdf (6.28 Ko)
Télécharger le fichier
RLGH_heap_label+linkage_1.pdf (6.39 Ko)
Télécharger le fichier
algo-chac.pdf (4.51 Ko)
Télécharger le fichier
algo-chac_fusion-labels.pdf (4.5 Ko)
Télécharger le fichier
ambroise_etal_AMB2019-suppmat.pdf (783.52 Ko)
Télécharger le fichier
article_comptime_dots.png (71.03 Ko)
Télécharger le fichier
article_di_full.png (62.2 Ko)
Télécharger le fichier
pencil_large_h.pdf (33.56 Ko)
Télécharger le fichier
pencil_small_h.pdf (33.55 Ko)
Télécharger le fichier
snp_comptime_p.png (121.99 Ko)
Télécharger le fichier
snp_firstDiff.png (103.31 Ko)
Télécharger le fichier
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Origine : Fichiers produits par l'(les) auteur(s)