Standard error of the genetic correlation: how much data do we need to estimate a purebred-crossbred genetic correlation?
Résumé
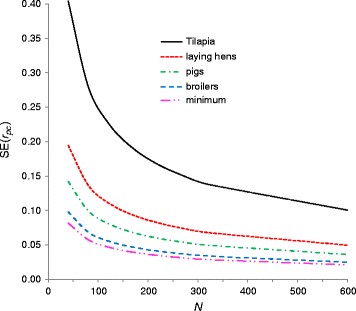
AbstractBackgroundThe additive genetic correlation (rg) is a key parameter in livestock genetic improvement. The standard error (SE) of an estimate of rg, r^g, depends on whether both traits are recorded on the same individual or on distinct individuals. The genetic correlation between traits recorded on distinct individuals is relevant as a measure of, e.g., genotype-by-environment interaction and for traits expressed in purebreds vs. crossbreds. In crossbreeding schemes, rg between the purebred and crossbred trait is the key parameter that determines the need for crossbred information. This work presents a simple equation to predict the SE of r^g between traits recorded on distinct individuals for nested full-half sib schemes with common-litter effects, using the purebred-crossbred genetic correlation as an example. The resulting expression allows a priori optimization of designs that aim at estimating rg. An R-script that implements the expression is included.ResultsThe SE of r^g is determined by the true value of rg, the number of sire families (N), and the reliabilities of sire estimated breeding values (EBV):SEr^g≈1ρx2ρy2+1+0.5ρx4+0.5ρy4-2ρx2-2ρy2rg2+rg4N-1,where ρx2 and ρy2 are the reliabilities of the sire EBV for both traits. Results from stochastic simulation show that this equation is accurate since the average absolute error of the prediction across 320 alternative breeding schemes was 3.2%. Application to typical crossbreeding schemes shows that a large number of sire families is required, usually more than 100. Since SEr^g is a function of reliabilities of EBV, the result probably extends to other cases such as repeated records, but this was not validated by simulation.ConclusionsThis work provides an accurate tool to determine a priori the amount of data required to estimate a genetic correlation between traits measured on distinct individuals, such as the purebred-crossbred genetic correlation.
Domaines
Sciences du Vivant [q-bio]
Fichier principal
 12711_2014_Article_79.pdf (369.35 Ko)
Télécharger le fichier
12711_2014_79_MOESM1_ESM.zip (1.39 Ko)
Télécharger le fichier
12711_2014_79_MOESM2_ESM.pdf (445.32 Ko)
Télécharger le fichier
12711_2014_79_MOESM3_ESM.xlsx (155.27 Ko)
Télécharger le fichier
12711_2014_79_MOESM4_ESM.gif (6.78 Ko)
Télécharger le fichier
12711_2014_79_MOESM5_ESM.gif (8.3 Ko)
Télécharger le fichier
12711_2014_Article_79.pdf (369.35 Ko)
Télécharger le fichier
12711_2014_79_MOESM1_ESM.zip (1.39 Ko)
Télécharger le fichier
12711_2014_79_MOESM2_ESM.pdf (445.32 Ko)
Télécharger le fichier
12711_2014_79_MOESM3_ESM.xlsx (155.27 Ko)
Télécharger le fichier
12711_2014_79_MOESM4_ESM.gif (6.78 Ko)
Télécharger le fichier
12711_2014_79_MOESM5_ESM.gif (8.3 Ko)
Télécharger le fichier
{kind=link}
{kind=link}
Origine : Publication financée par une institution
Origine : Publication financée par une institution
Origine : Publication financée par une institution
Origine : Publication financée par une institution
Origine : Publication financée par une institution
Origine : Publication financée par une institution