Audio-Visual Speaker Localization via Weighted Clustering
Résumé
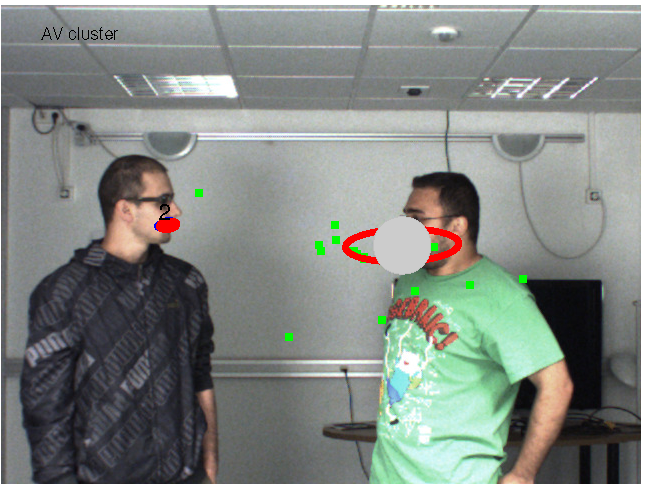
In this paper we address the problem of detecting and locating speakers using audiovisual data. We address this problem in the framework of clustering. We propose a novel weighted clustering method based on a finite mixture model which explores the idea of non-uniform weighting of observations. Weighted-data clustering techniques have already been proposed, but not in a generative setting as presented here. We introduce a weighted-data mixture model and we formally devise the associated EM procedure. The clustering algorithm is applied to the problem of detecting and localizing a speaker over time using both visual and auditory observations gathered with a single camera and two microphones. Audiovisual fusion is enforced by introducing a cross-modal weighting scheme. We test the robustness of the method with experiments in two challenging scenarios: disambiguate between an active and a non-active speaker, and associate a speech signal with a person.
Fichier principal
 mainCameraReady-HAL.pdf (1.05 Mo)
Télécharger le fichier
mainCameraReady-HAL.pdf (1.05 Mo)
Télécharger le fichier
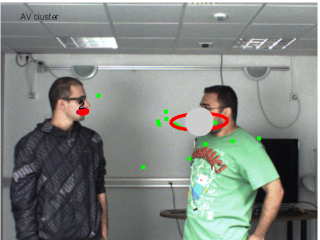 result-mlsp.png (446.02 Ko)
Télécharger le fichier
result-mlsp.png (446.02 Ko)
Télécharger le fichier
{kind=link}
Origine : Fichiers produits par l'(les) auteur(s)
Format : Figure, Image
Loading...